Processes and Messages
A message in Orchesty is a single payload that a node receives, transforms, and forwards. A process is the execution record of a topology run: every node visit it performed, the results those visits produced, and any messages that failed along the way.
This split is the core of Orchesty's reliability story.
Messages are persisted at every step #
Every queue is durable. When a node returns a message, the platform writes it to storage before acknowledging the producer and before enqueuing it for the next consumer. This means:
- A node crashing mid-processing does not lose the input message; the platform redelivers it.
- A worker crashing during the response does lose the response, but the previous step still has the input persisted, so the platform redelivers and the consumer gets a second chance.
- Power-cycling the host is safe; queues survive.
Persistence is not optional. Every step is at-least-once delivery. Your nodes should be idempotent for the parts where double execution is harmful (e.g. third-party POST calls; use ID mapping or sync-aware connectors).
Processes are tracked end to end #
When a topology is triggered, the platform creates a process record with a unique id. As the run progresses, the process keeps:
- All node traversals that have happened so far.
- The expected set of traversals, so the platform knows when the process is complete (a fan-out into N branches counts as N expected children).
- The count of failed messages for the process.
- Each failed message in detail — payload, error, the node where it failed — listable from the Trash.
- Per-node logs, including the inputs and outputs each node handled.
A process can have many inputs and many outputs — fan-out, fan-in, multiple external API calls, multiple emitted results. The platform doesn't compress that into a single "input" and "output"; the per-node log is the source of truth.
In the Admin UI you can see the process evaluation (which nodes succeeded, which failed, basic metrics) from the topology detail and the Processes view. Failed messages of any process are listable and actionable in the Trash (see below).
Retries #
Each connector has a configurable retry policy: number of attempts, backoff, which error types are retryable. Retryable errors stay in the queue until the policy is exhausted. Non-retryable errors short-circuit the policy and route to the next stage.
Failed messages and the Trash #
When a message exhausts its retries, the platform routes it to the Trash: a per-topology inbox of failed messages. Trash entries hold the original payload, the error, and the node where the failure happened.
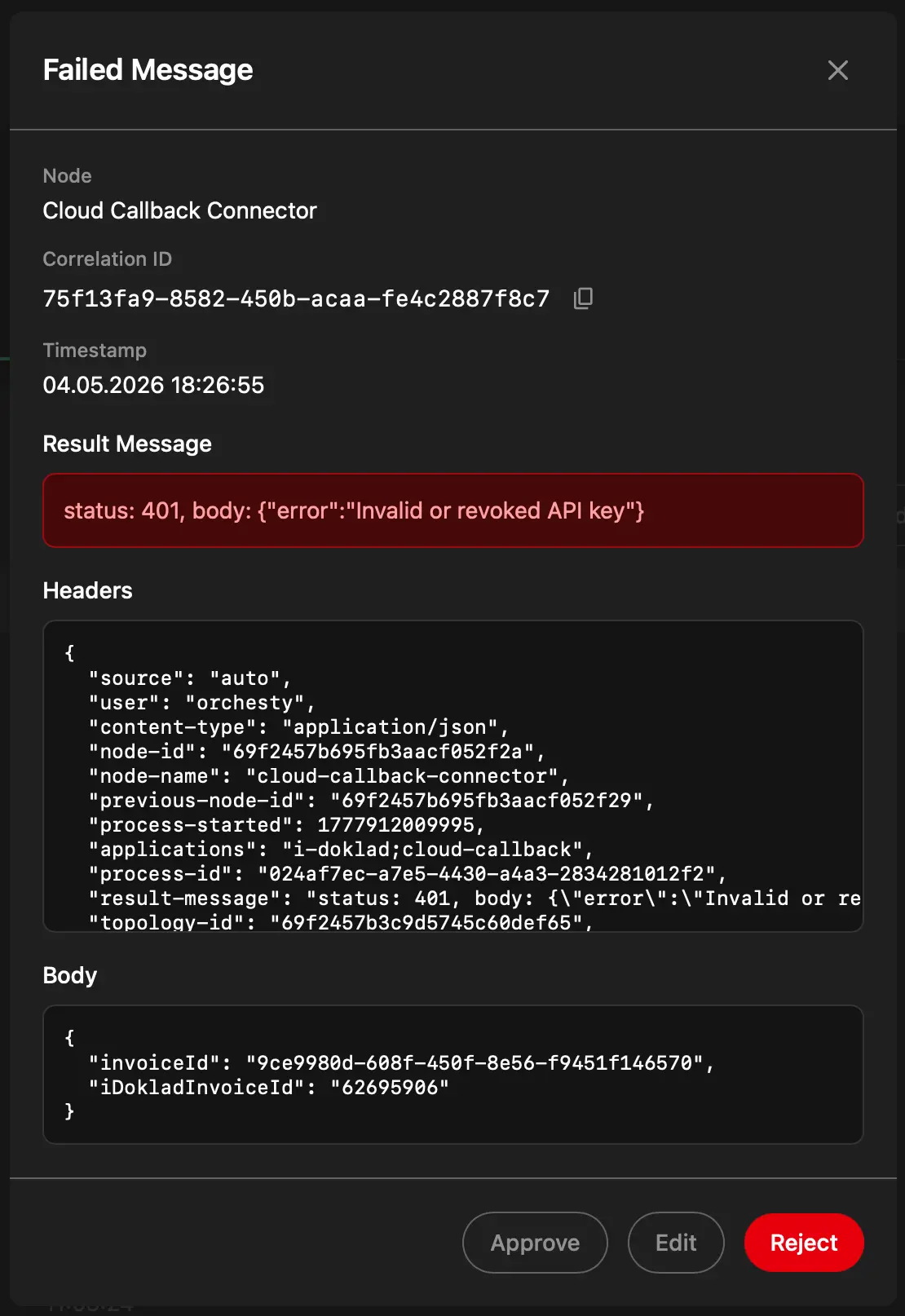
From the Trash, an operator can:
- Inspect the payload, the error, and the failing node.
- Edit the payload and re-run from the failed step (useful when the upstream system fixes a bad record).
- Bulk re-run a group (useful when a downstream API was down and is now back).
- Discard the message.
This is also the channel for operational notifications: failed messages can trigger alerts so operators know to look at the Trash.
Why this matters #
The combination of per-step persistence, durable queues, the process record, and the Trash inbox means that you never have to write your own retry / dead-letter / replay logic. Build one node at a time; the platform handles the rest.
See also #
- Topologies — what a process is an execution of.
- Building nodes: Error handling and retries — the in-code side.
- Operations: Trash inbox — what an operator does with failed messages.
- Operations: Notifications — how to wire alerts to Trash events.
- Development: Trace auditing (Pro & Enterprise).