Five Core Principles That Make Orchesty Different
The five architectural choices behind Orchesty, and what each of them gives you in practice when integrations have to stay reliable, observable, and defensible at scale.
If you are evaluating an integration platform for workloads that actually matter (orders, payments, inventory, customer data, anything where silent failures cost money or trust), what makes a platform different is rarely a feature list. It is a small number of architectural choices that decide how the system behaves under volume, under failure, and over time.
Orchesty is built around five such choices. Each of them gives you something that is otherwise hard to engineer: durable parallel throughput, isolation between integrations, ownership of your own code, defensible visibility into what happened, and the freedom to deploy where regulation and business require. The rest of this page walks through them in turn, with a Go deeper link to the longer Basics article behind each principle.
1. Streaming, not workflows #
If your integrations matter, they should not be scripts that start and stop with each event.
Orchesty is built as a continuously running data pipeline rather than a workflow engine. Data enters and flows through a chain of steps, where each step picks up work as it becomes available. There are no per-event start-up costs and no global execution timeout. The pipeline simply keeps moving as long as data keeps arriving.
What this gives you in practice:
- Throughput at scale. A single message and a million messages flow through the same warm pipeline. There is no per-event boot cost to amortise, so spikes do not trigger a separate cost or stability cliff.
- No timeouts to engineer around. A slow downstream system does not kill your work; the data simply waits for the next step to be ready and proceeds at the rate the target system allows.
- Reliability is structural. The state of every in-flight item lives inside the pipeline itself, not inside a transient process that can disappear. Crashes, restarts, and deployments do not lose data; they pause it.
- Backpressure is native. When one step slows down, the queue in front of it grows. The platform sees this immediately and protects the rest of the system, instead of letting failures cascade.

For traffic where volume, reliability, and predictability matter more than the cosmetics of "this triggers that", a streaming pipeline is the right primitive. Orchesty is one from the ground up.
→ Go deeper: Streaming integration
2. Topologies are live infrastructure, not scripts #
Your integrations stop being scripts that run on demand. They become a permanent piece of infrastructure: always on, always ready to take in data, and always preserving state along the way.
In Orchesty, every integration is materialised as its own running pipeline, with each step connected to the next by a persistent channel that holds the data until the next step is ready to take it. Each pipeline is also its own isolated unit; what is happening in one integration cannot reach into another.
This single design choice gives you several things that are otherwise hard to engineer:
- Built-in persistence. When something fails (a third-party API, a misbehaving step, an unexpected payload), your data does not disappear. It stops at exactly the place that failed and waits there until it can continue.
- Massive parallelism by default. Each step processes independently from the others. Big spikes do not congest the pipeline; they fill it. The platform does the work of holding back what cannot proceed yet, instead of letting it become a bottleneck you have to engineer around.
- Operational isolation between integrations. A misbehaving integration cannot starve, slow down, or take down the others. The blast radius of a bad release is structurally limited to the one integration that caused it.
- Reversible, zero-downtime deployments. Publishing a new version creates a new running pipeline alongside the old one. In-flight work finishes on the previous version, new work routes to the new one, and rolling back is re-enabling the previous version.

For anyone putting critical traffic on the platform, this turns "what happens when it goes wrong" from a runbook problem into a property of the platform.
→ Go deeper: Topologies: anatomy of a data pipeline
3. Your code is your inventory, not the vendor's #
The integration code that runs your business should live in your repository, with your version control, your CI, and your code reviews. In Orchesty, it does.
Orchesty separates two layers. The platform owns orchestration: scheduling, routing, retries, scaling, observability. You own the integration code: the small components that talk to specific external systems and do specific jobs. Those components live in your own deployable services, alongside the rest of your software, and you publish them to Orchesty just like you would register any other service in your stack.
What this gives you in practice:
- Code ownership where it matters. Connectors, transformations, and custom logic stay in your repository under your engineering process. There is no vendor lock-in on the most valuable layer of your integration estate.
- A catalogue of open-source connectors. Common third-party systems already have ready-made, open-source connectors you can install into your services and start using. You contribute back when it makes sense.
- A source-available platform core. The orchestration layer itself is source-available, so you can read it, audit it, and patch it if your environment requires that level of control.
- Works in any network environment. Whether your services live behind a public URL or inside a closed network with no inbound access, the platform can reach them. Local development, on-premise deployments, and isolated VPCs all work without VPNs or open ports.
- AI-friendly by design. The building blocks are small and well-defined enough that modern AI tools, with the published Orchesty rulesets, can scaffold connectors and entire integrations correctly. Boilerplate stops being a tax on every new connection.

You keep what matters (the business logic) inside your own engineering process. The platform takes care of everything that should be invisible.
→ Go deeper: Workers & Components · Working with Orchesty
4. You see what your integrations did, and you can prove it #
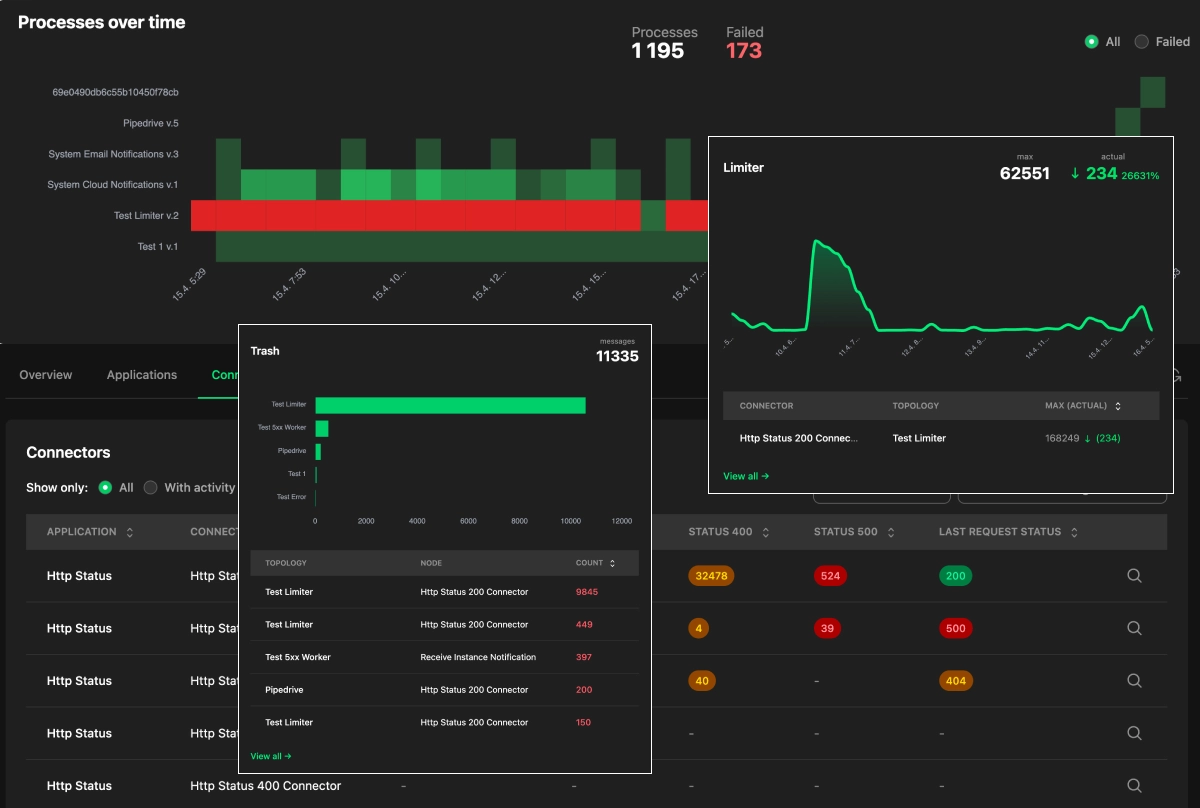
Most integration platforms tell you that something happened. Orchesty captures the what, when, and with which result of every process and every external call as operational data, not as a line buried in a log file — and gives operators the views and actions they need to act on it without engineering help.
The dashboards do not pretend to be a real-time event stream. The platform collects metrics from every component (workers, connectors, the Limiter, the Trash, the process evaluator) on a one-minute cadence and aggregates them. In production, where processes flow faster than any browser could ever paint, that is the right trade-off. What you get instead is a layered, drillable view of the system, tied together by correlation IDs rather than a single monolithic record:
- Heatmap of topologies and time slots. Each slot summarises a topology's processes for a window. A single failure paints the slot red — no need to read logs to know something went wrong.
- Application heatmap. The same shape, but grouped by the integrated application. One glance tells you whether an entire upstream service has gone dark, so you can answer "why is process X not running" with evidence in seconds.
- Drill-down to one process. From any failed slot you reach the process detail: which nodes failed, when in time, what the connector returned, and which messages ended up in the Trash.
- Trash inbox actions. Failed messages are first-class objects you can approve, edit, or reject — individually or in bulk — straight from the Admin UI.
- Limiter view. When upstream rate limits are the bottleneck, the Limiter view shows how many messages are queued per application and how long the current backlog will take to drain. Operators can terminate specific processes — or an entire topology that is producing the overload — to free the queue.
What this gives you in practice:
- Confidence in production. You see problems as the next metric tick comes in, including issues that are clearly upstream's fault rather than yours, with the evidence to escalate immediately.
- Defensible against partner disputes. Per-connector communication is captured in the platform's logs, so when a vendor claims they never received a message you can show the exact request, the exact response, and the timestamp.
- Faster recovery. Operators handle Trash entries in the Admin UI: approve, edit the payload, reject, or bulk-resolve a whole incident — without code changes or rebuilding state by hand.
- Audit beyond a single process — with Trace. Reconstructing the full history of one business entity across every topology that ever touched it (the order ABC-123 over the last quarter question) is the job of the Trace feature (Pro & Enterprise). Trace assembles those reports from process logs using entity keys you define, with a real delivery status badge at every boundary call. Available history is bound by your log retention policy — today's platform doesn't hold an unbounded multi-year audit trail, and the practical horizon depends on the retention configured for your instance.
For organisations whose integrations sit on the path of money, inventory, customer data, or compliance, this is what makes them defensible — without overpromising what the platform records on its own today.
→ Go deeper: Operational visibility · Observability in practice · Trace auditing
5. Deployment is a runtime decision, not an architectural one #
Where you run Orchesty depends on what your business needs today. It can change tomorrow without redesigning anything.
The same integrations, the same components, and the same operational tooling run on Orchesty's shared cloud, on a dedicated single-tenant environment, or fully inside your own infrastructure. You can also combine modes (keep sensitive workloads inside your perimeter, less sensitive ones in the cloud) and operate the whole thing as one unified estate.
What this gives you in practice:
- Start fast, move when you need to. Build on the managed cloud while you are validating the platform; move to a dedicated environment or on-premise installation when regulation, scale, or strategy requires it. The integrations themselves do not change.
- Full data sovereignty when on-premise. Your encryption keys, your secrets, your storage, and your observability data stay inside your perimeter. Nothing has to leave.
- Region pinning and dedicated infrastructure for regulated workloads. When data residency, single-tenancy, or custom SLAs are non-negotiable, the same platform supports them without forking the product.
- Hybrid setups for organisations that do not fit one box. Sensitive workloads on-premise, less sensitive ones in the cloud, connected securely and observed from one place. Region-local processing with a central control plane is a supported architecture, not a custom project.
- Future-proof against changing constraints. New regulation, a new geography, an acquisition, or a shift in strategy does not force a redesign. The platform follows the business.
Deployment becomes a business decision (regulation, compliance, geography, budget), not an architectural commitment. When the constraints change, the integrations stay the same.
→ Go deeper: Deployment flexibility
Where next #
These five principles are why Orchesty is built the way it is. From here, the most useful next steps depend on what you came for:
- Build something hands-on. Walk through your first integration end-to-end in Get Started.
- Go into the technical reference. The platform's architecture is documented in detail in Documentation: Architecture.
- Look at concrete patterns. Common implementation patterns and recipes live in Learn / Guides.